Le scraping web est une technique utilisée pour extraire des informations de pages web de manière automatisée. Si l’on traduit sa signification de l’anglais, cela reviendrait à dire quelque chose comme « déterrer un site web ».
Applications et exemples : à quoi sert le web scraping ?
Son utilité est très claire : nous pouvons tirer parti du scan du Web pour obtenir des quantités industrielles d’informations (big data) sans avoir à taper un seul mot. Grâce aux algorithmes de recherche, nous pouvons explorer des centaines de sites web pour n’en extraire que les informations dont nous avons besoin.
Pour ce faire, il sera très utile de maîtriser les regex (expression régulière) pour limiter les recherches ou les rendre plus précises et mieux filtrer les informations.
- Quelques exemples pour lesquels nous aurons besoin de web scraping :
- Pour le marketing de contenu : nous pouvons concevoir un robot qui « extrait » des données spécifiques d’un site web et nous en servir pour générer notre propre contenu. Exemple : extraction de données statistiques du site officiel d’une ligue de football pour générer notre propre base de données.
- Pour gagner en visibilité sur les réseaux sociaux : nous pouvons utiliser les données d’un scrape pour interagir par le biais d’un robot avec les utilisateurs sur les réseaux sociaux. Exemple : créer un bot sur instagram qui sélectionne les liens de chaque photo et programme ensuite un commentaire sur chaque post.
- Contrôler l’image et la visibilité de notre marque sur Internet : par le biais d’un scrapeo, nous pouvons automatiser le positionnement de divers articles de notre site web dans Google ou, par exemple, contrôler la présence de notre marque dans certains forums. Exemple : suivi de la position dans Google de tous nos articles de blog.
Comment fonctionne le web scraping ?
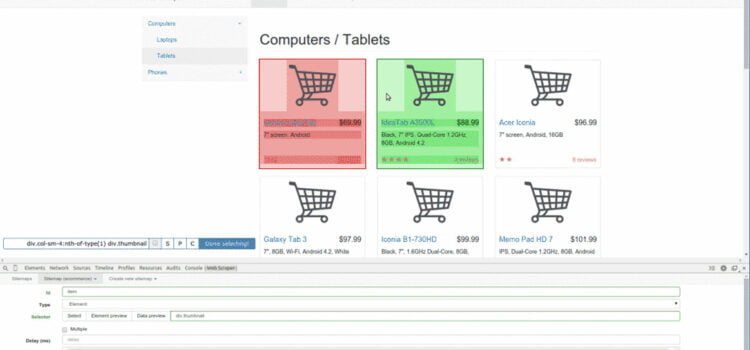
Prenons un exemple de base du fonctionnement d’un scrape web.. Imaginons que nous soyons intéressés par l’extraction du titre de 400 pages ayant le même format et situées sur le même site.. Sur chacune des 400 pages, le titre se trouve à l’intérieur d’un sélecteur <h1>, qui lui-même se trouve à l’intérieur d’un <div> avec la classe .header.
Notre scraper web va détecter le sélecteur h1 dans la classe d’en-tête (.header h1) et extraire cette information dans chacune de ces 400 pages. Nous pourrons ensuite obtenir toutes ces informations en exportant les données dans des formats tels qu’une liste .json ou un fichier .csv.
Ce qui nécessiterait quelques heures d’ennui absolu et de travail mécanique manuel, notre scraper web peut le faire en quelques minutes seulement.
Quelles sont les compétences nécessaires pour devenir un bon scraper ?
Le web scraping est une discipline qui doit combiner deux aspects très différents de la connaissance du web, tous deux essentiels pour avoir un profil polyvalent sur le web. D’une part, nous devons maîtriser la visualisation des données au niveau conceptuel, et d’autre part, nous devons disposer des connaissances techniques nécessaires pour pouvoir extraire les données avec précision à l’aide d’outils spécialisés.
En fin de compte, cela se résume à savoir comment gérer de grandes quantités de données (big data). Nous devons être un minimum familiarisés avec la visualisation de grandes quantités de données afin de pouvoir hiérarchiser et interpréter les données que nous extrayons d’un site web. Et non seulement pour extraire les données, mais aussi lors de la planification de la stratégie d’extraction, nous devons savoir quelles données nous allons extraire afin de pouvoir leur donner un sens informatif pour l’utilisateur.
Il y a 3 points clés à maîtriser pour être un bon scraper web :
1) Connaissance de la mise en page web. Le scraper web fonctionne en sélectionnant des sélecteurs html et pour cela nous devrons avoir quatre connaissances de base de l’architecture web.
2. savoir utiliser un logiciel pour visualiser les données, tel qu’un tableur Google, connu sous le nom de Google Spreadsheets, ou un éditeur de texte basique tel que Sublime.
3. avoir une connaissance des regex. Une connaissance minimale des regex (également appelés expressions régulières) nous facilitera grandement la tâche lorsque nous travaillerons avec de grandes quantités de données, car cela peut nous épargner des milliers d’heures de travail laborieux lors de la correction ou du débogage des données avant de les importer sur la plate-forme souhaitée.




