
L’apprentissage par transfert est l’une des techniques de Deep Learning les plus importantes pour l’apprentissage automatique en intelligence artificielle. Il consiste, en substance, à tirer parti d’une grande quantité d’informations liées à la résolution d’un problème et à les utiliser sur un problème différent, mais qui partage certaines caractéristiques avec celui-ci. En d’autres termes, il s’agit de modifier des modèles déjà entraînés (ou des réseaux neuronaux) à reconnaître certaines caractéristiques afin de pouvoir en reconnaître d’autres similaires. La vision artificielle et le traitement du langage naturel sont les missions pour lesquelles ils réservent les meilleurs résultats.
Bases de l’apprentissage par transfert
L’origine historique des idées contenues dans l’apprentissage par transfert est liée à certains algorithmes utilisés dans l’apprentissage automatique. Cela a conduit au développement de divers concepts pour l’apprentissage multitâche. L’étape suivante a consisté à formaliser ces découvertes afin d’élargir autant que possible le nombre de problèmes à traiter.
Aujourd’hui, il est possible d’appliquer une formulation statistique très rigoureuse. Les termes essentiels dans ce domaine de connaissances sont : un champ ou un domaine de caractéristiques, une tâche définie numériquement et une fonction de probabilité. Grâce à l’abstraction mathématique, vous multipliez la puissance de la théorie pour l’appliquer à une vaste collection de tâches. Grâce à la classification automatique des images, vous obtenez un exemple assez clair du fonctionnement de l’apprentissage par transfert. L’approche générale de ce travail, pour l’apprentissage profond, consisterait à découvrir une architecture de réseau neuronal qui accélère l’apprentissage. Ensuite, il resterait à donner des valeurs de départ aux paramètres qui servent de variables d’entrée aux différentes couches du réseau.
C’est là que l’apprentissage par transfert permet de gagner du temps et de disposer d’une ressource informatique gigantesque. Avec des données obtenues à partir d’une tâche similaire, mais plus générique, vous évitez les approximations coûteuses d’un point de départ optimal. L’étape suivante consiste à ajouter des couches jusqu’à ce que les valeurs obtenues correspondent, à un pourcentage acceptable, à celles fournies par une intelligence humaine.
Réseaux neuronaux convolutifs
Les réseaux convolutifs ne sont rien d’autre qu’un type de réseau neuronal spécialisé dans l’appréciation des propriétés visuelles des objets. Ces caractéristiques conduisent immédiatement à une identification artificielle qui simule la vision humaine. C’est en discriminant les caractéristiques significatives de celles qui ne le sont pas que le réseau neuronal parvient à générer cet effet.
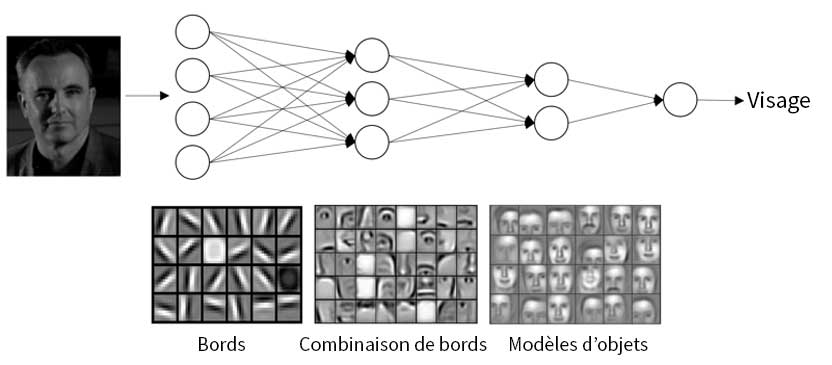
Le terme “convolution” vient des mathématiques et décrit une fonction appliquée à une autre. Il s’agit d’une opération de base dans le processus d’obtention d’informations par ce type de réseau neuronal, une modélisation du fonctionnement du cortex cérébral responsable de la vision chez l’être humain. Ainsi, le processus artificiel qui imite la vision écarte les différences internes entre une même catégorie d’objets. Cette discrimination des particularités accidentelles est essentielle, car elle garantit une attribution d’étiquettes qui a une forte probabilité d’être correcte.
Toutefois, le nombre d’images fournies pour la formation devra être élevé, car ces éléments graphiques sont analysés en différenciant chacune de leurs parties sur la base de la couleur. La division est effectuée par la machine, en séparant l’espace de surface en grilles pixellisées qui fourniront des informations numériques.
C’est là qu’interviennent les convolutions. Elles consistent à introduire un groupe de pixels voisins de taille inférieure à celle de l’image. Ils y chercheront des motifs par comparaison avec l’image qui fait l’objet de la classification automatique. Les superpositions sur l’image produisent à leur tour une nouvelle matrice de données. Ces groupes de pixels voisins sont appelés “noyau”, et le regroupement des noyaux est appelé “filtre”.
Sur les convolutions produites, une fonction d’activation est ajoutée et une cartographie de dimensions identiques à l’image originale est obtenue. Enfin, le max-pooling est appliqué pour générer de nouvelles sorties. Plus les formes sont complexes, plus le nombre de convolutions est élevé.
Apprentissage par transfert et traitement du langage naturel
Le traitement du langage naturel (NLP) est l’un des plus grands défis dans le domaine de l’intelligence artificielle. Mais l’apprentissage par transfert contribue de manière décisive à l’obtention de résultats prometteurs. Ici, l’attribution d’étiquettes identifiant un fragment de langage est améliorée en réduisant le contenu à un sujet spécifique.
La stratégie à suivre peut se résumer aux étapes suivantes.
- sélectionner un modèle qui servira de point de départ. Les données à appliquer ne se limitent pas à la prise en compte de mots isolés. Elles impliquent également les relations de proximité de la parole entre eux. Cela nécessite une formalisation très intensive d’une langue.
- Appliquer l’apprentissage par transfert au modèle précédent. La base de données sur laquelle vous travaillez doit provenir d’un domaine spécifique. Et grâce à un corpus linguistique, vous effectuerez différentes opérations qui vous permettront d’identifier le plus grand nombre de caractéristiques significatives.
- Créer des catégories pour classer en groupes étiquetés par un sens contenu dans les textes.
En conclusion, il faut comprendre que l’apprentissage par transfert est un élément fondamental de l’apprentissage automatique. Nous savons que les techniques qui appliquent ce transfert en sont encore à leurs balbutiements, avec une évolution qui semble prometteuse. Mais l’abondance de modèles pré-entraînés laisse déjà entrevoir des avancées technologiques encore impensables il y a quelques années.




